Vom Prompt zum Prototypen in unter 3 Stunden
Wie ich mit KI-Unterstützung eine vollständige UX-Simulation entwickelt habe – inklusive der Momente, wo nichts funktionierte wie gedacht.
Transparenzhinweis: Dieser Artikel wurde auf Basis meiner eigenen Erfahrungen und des vollständigen Projektverlaufs mit Unterstützung von Claude (Anthropic) verfasst. Die Inhalte, Bewertungen und Einschätzungen stammen aus meiner Arbeit – die Formulierung hat die KI übernommen. Ich halte das für eine faire und ehrliche Nutzung.
Es gibt Experimente, die man nur macht um einer Frage nachzugehen: Wie weit kommt man wirklich mit KI, wenn man einen Prototypen von Grund auf neu baut? Ich wollte keine Demo-Anwendung, kein Spielzeug – sondern etwas Reales. Eine Simulation, die man echten Testnutzern in die Hände geben kann.
Das Ergebnis: eine voll funktionsfähige interaktive Webanwendung mit drei Nutzerpfaden, Schritt-für-Schritt-Wizards, Inline-Datenbearbeitung, Feedback-System und Auswertungsseite. Entstanden in einer einzigen Session, in etwa zwei bis drei Stunden – und mit mehr Stolpersteinen, als ich am Anfang erwartet hatte.
Das Experiment
Ich arbeite gerade an einem UX-Forschungsprojekt, bei dem wir verschiedene Methoden zum Datenimport in ein HR-System vergleichen möchten. Konkret: Wie importiert man Weiterbildungshistorien von Mitarbeitern? Über eine vorgefertigte Excel-Vorlage? Über eine eigene Datei mit automatischer Spaltenerkennung? Oder per Foto- oder PDF-Scan, wo eine KI die Tabelle extrahiert?
Um echte Nutzerfeedbacks zu sammeln, brauche ich keine echte Datenverarbeitung – ich brauche eine überzeugende Simulation. Nutzer sollen den Prozess vollständig durchlaufen können, sich wie in einem echten System fühlen, und am Ende jede Methode bewerten.
Das ist der Rahmen, mit dem ich an die KI herangegangen bin.
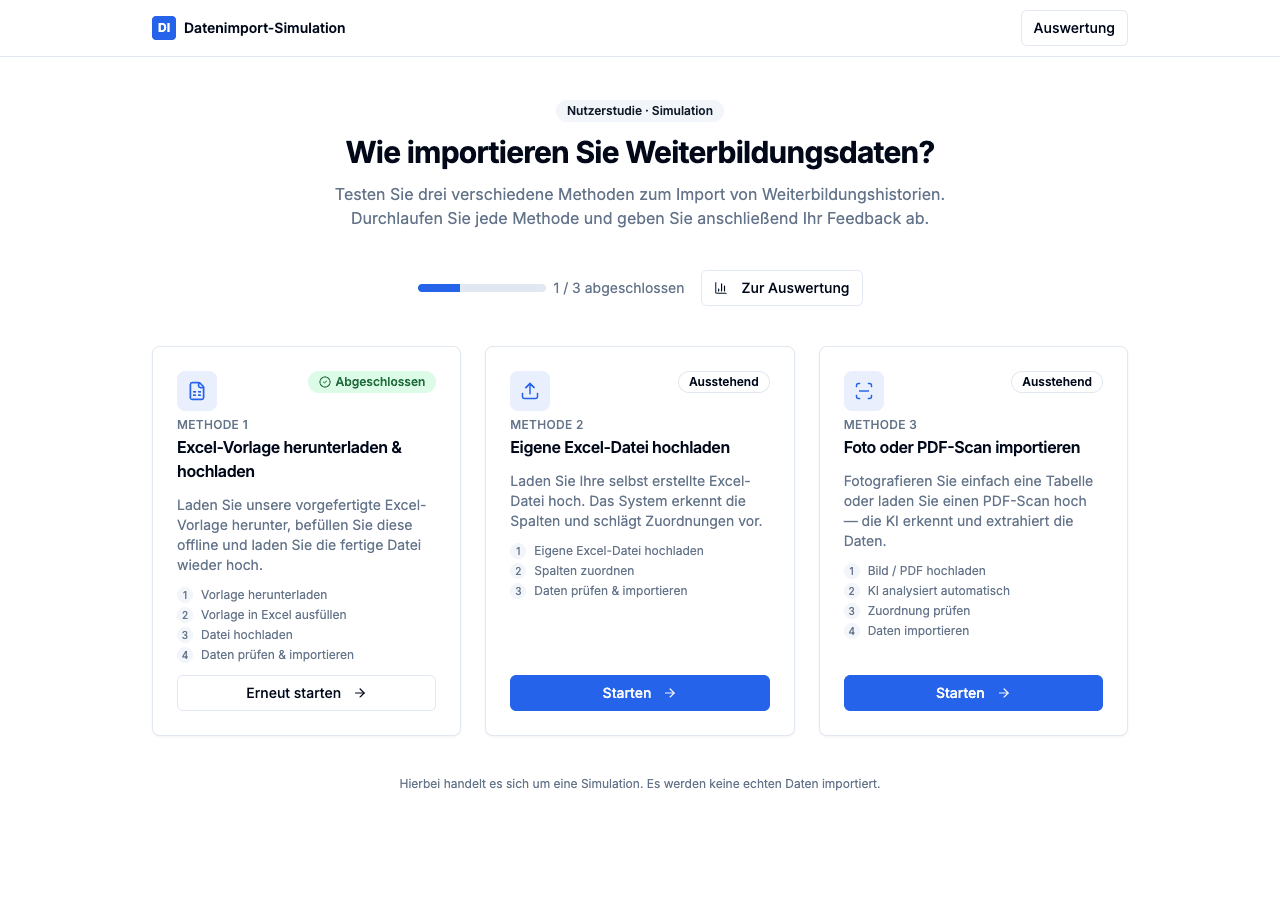 Die Startseite der Simulation – drei Methoden, ein Fortschrittsbalken, Methode 1 abgeschlossen.
Die Startseite der Simulation – drei Methoden, ein Fortschrittsbalken, Methode 1 abgeschlossen.
Der erste Prompt – und warum er entscheidend war
Was mir von Anfang an klar war: Je präziser mein erster Prompt, desto besser die Ausgabe. Ich habe keine kurze Anfrage geschickt. Mein erster Prompt war lang und detailliert – er beschrieb alle drei Importmethoden, das Konzept der Simulation mit Mock-Daten, die technologischen Vorgaben (Vue 3, shadcn-vue), und die Anforderung, alles sorgfältig zu dokumentieren da das Projekt in mehreren Sessions entstehen könnte.
Ich sage könnte, denn ich hatte ehrlich gesagt Bedenken, ob ein Abend dafür reicht. Das ist eines der Dinge, die mich am meisten überrascht haben: Es hat gereicht. Alles – Setup, drei vollständige Wizard-Flows, Mock-Daten, Feedback-System, Auswertungsseite, Screenshots – ist in einer einzigen Session entstanden.
Langen Prompt schreiben, auf Senden drücken, und dann mit der Umsetzung loslegen. So hatte ich mir das vorgestellt. Was ich stattdessen bekam, war kein Code – sondern ein Architekturplan.
Das war genau richtig. Der Plan durchlief drei Iterationen, bevor eine einzige Datei angelegt wurde: Zuerst die grobe Struktur, dann das Datenmodell mit 20 Feldern, dann die Detailanforderungen wie Inline-Dropdowns, Bestätigungsschritte und Mock-Daten-Struktur. Erst dann wurde gebaut.
Was das zeigt: KI ist kein Autocomplete-Werkzeug. Es ist ein Planungspartner – wenn man ihn so einsetzt.
Was überraschend gut funktionierte
Die Komplexität der Wizard-Flows
Jede der drei Methoden hat einen eigenen mehrstufigen Prozess – Methode 1 sechs Schritte, Methode 3 sogar sieben. Das bedeutet: State-Management über den gesamten Flow, persistente Datenhaltung im localStorage, gemeinsam genutzte Komponenten wie ColumnMappingPanel und ReviewTable, und ein Feedback-Formular am Ende jedes Pfades.
Die gesamte Komponentenstruktur – inklusive Pinia-Stores und Routing – war auf Anhieb kohärent. Ich musste kaum nachfragen.
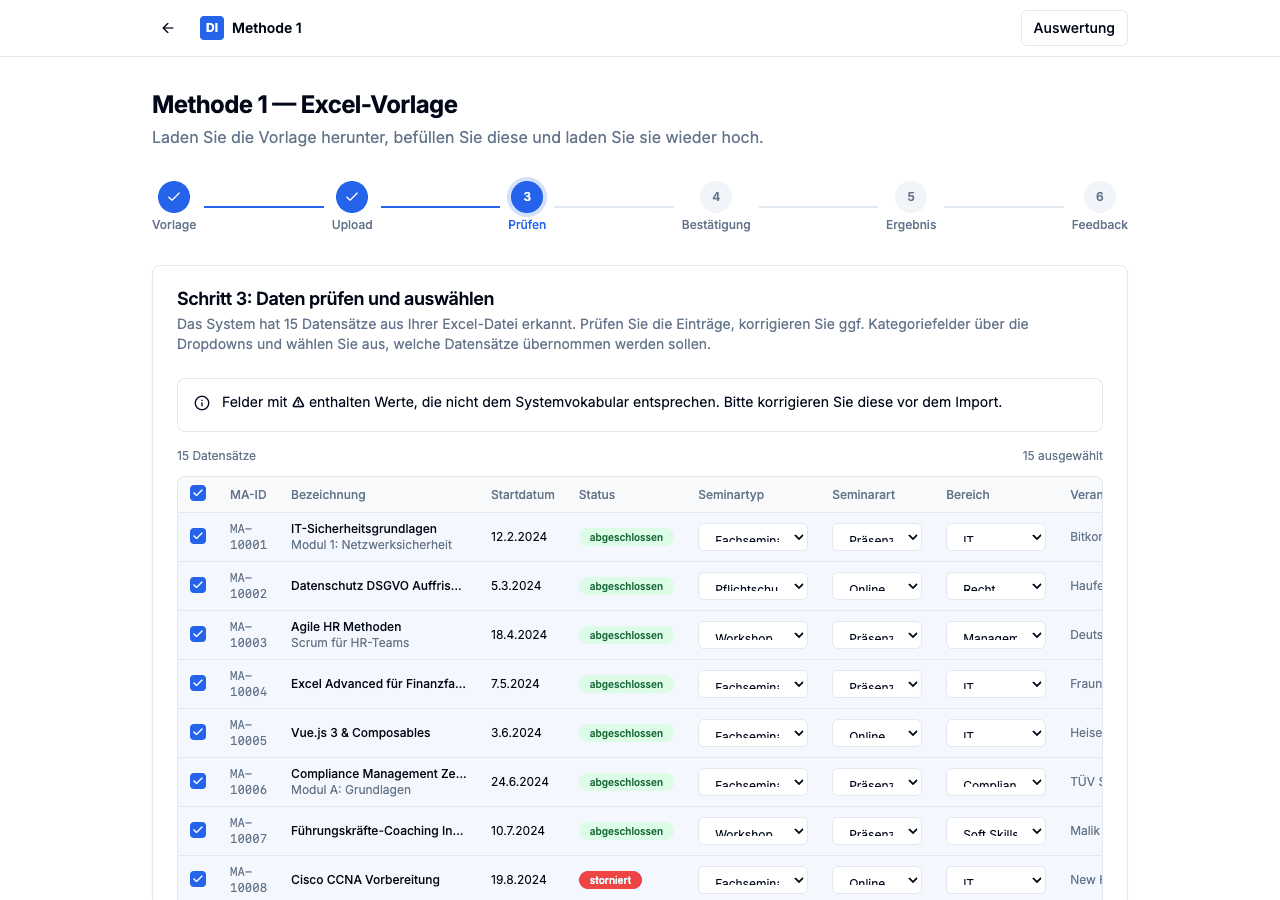 15 erkannte Datensätze, bearbeitbare Dropdowns, Warn-Icons für Werte außerhalb des Systemvokabulars.
15 erkannte Datensätze, bearbeitbare Dropdowns, Warn-Icons für Werte außerhalb des Systemvokabulars.
Die Spaltenzuordnung mit Konfidenz-Badges
Das war eine der Anforderungen, bei der ich nicht sicher war, ob sie in dieser Komplexität realisierbar ist: Ein Mapping-Interface, das automatisch erkannte Spalten als „Sicher" markiert, nicht erkannte als „Nicht erkannt" – und beim manuellen Zuordnen den Badge dynamisch auf „Manuell zugeordnet" wechselt.
Das hat beim ersten Anlauf funktioniert.
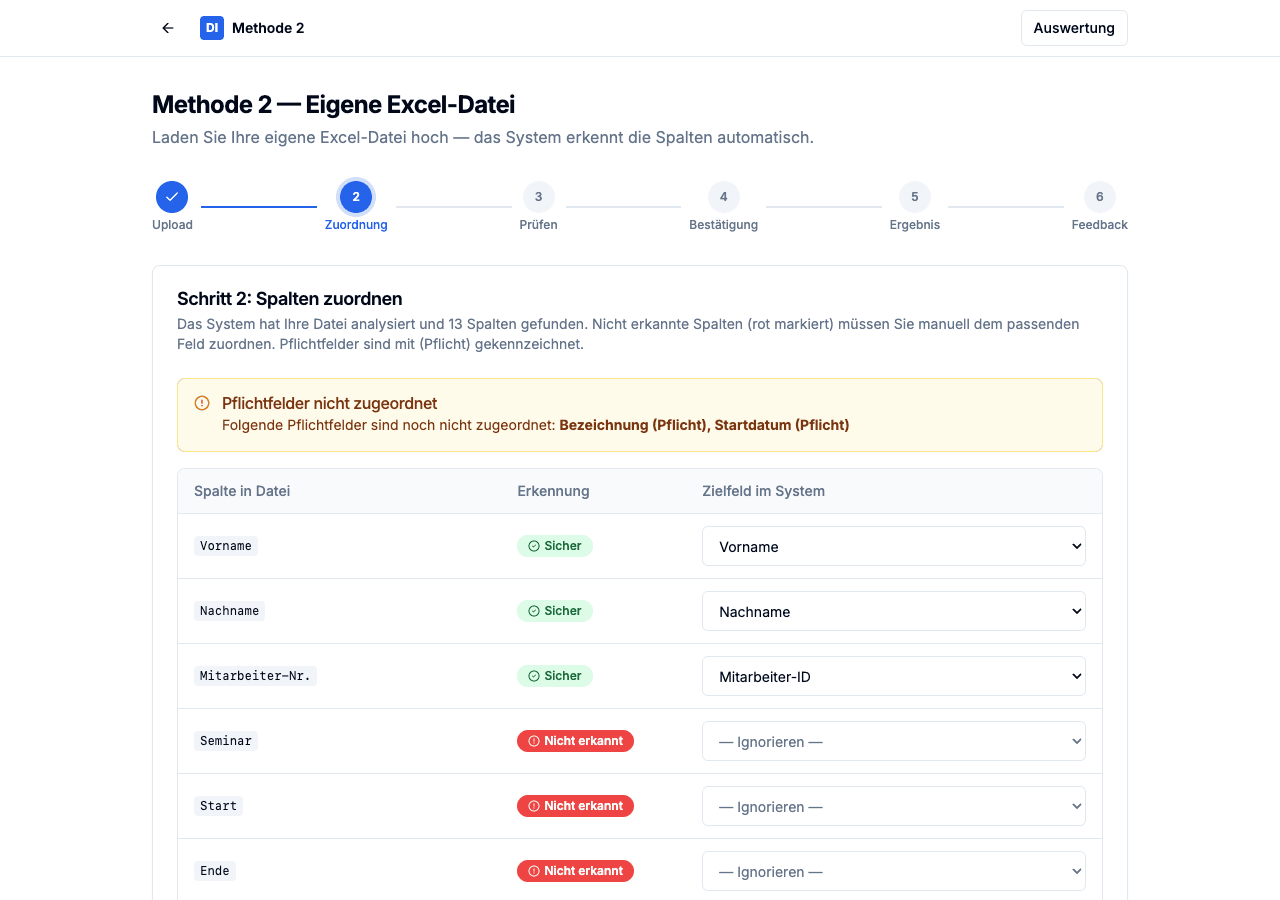 Drei Spalten sicher erkannt (grün), drei nicht erkannt (rot) – inklusive Warnung über fehlende Pflichtfelder.
Drei Spalten sicher erkannt (grün), drei nicht erkannt (rot) – inklusive Warnung über fehlende Pflichtfelder.
Die Auswertungsseite
Nach Abschluss aller drei Methoden erscheint eine Vergleichsseite: Sternebewertungen je Dimension, Nutzer-Zitate, und ein Gesamt-Fazit. Diese Seite wird direkt aus dem Pinia-Store gespeist – ohne ein Backend, ohne eine API.
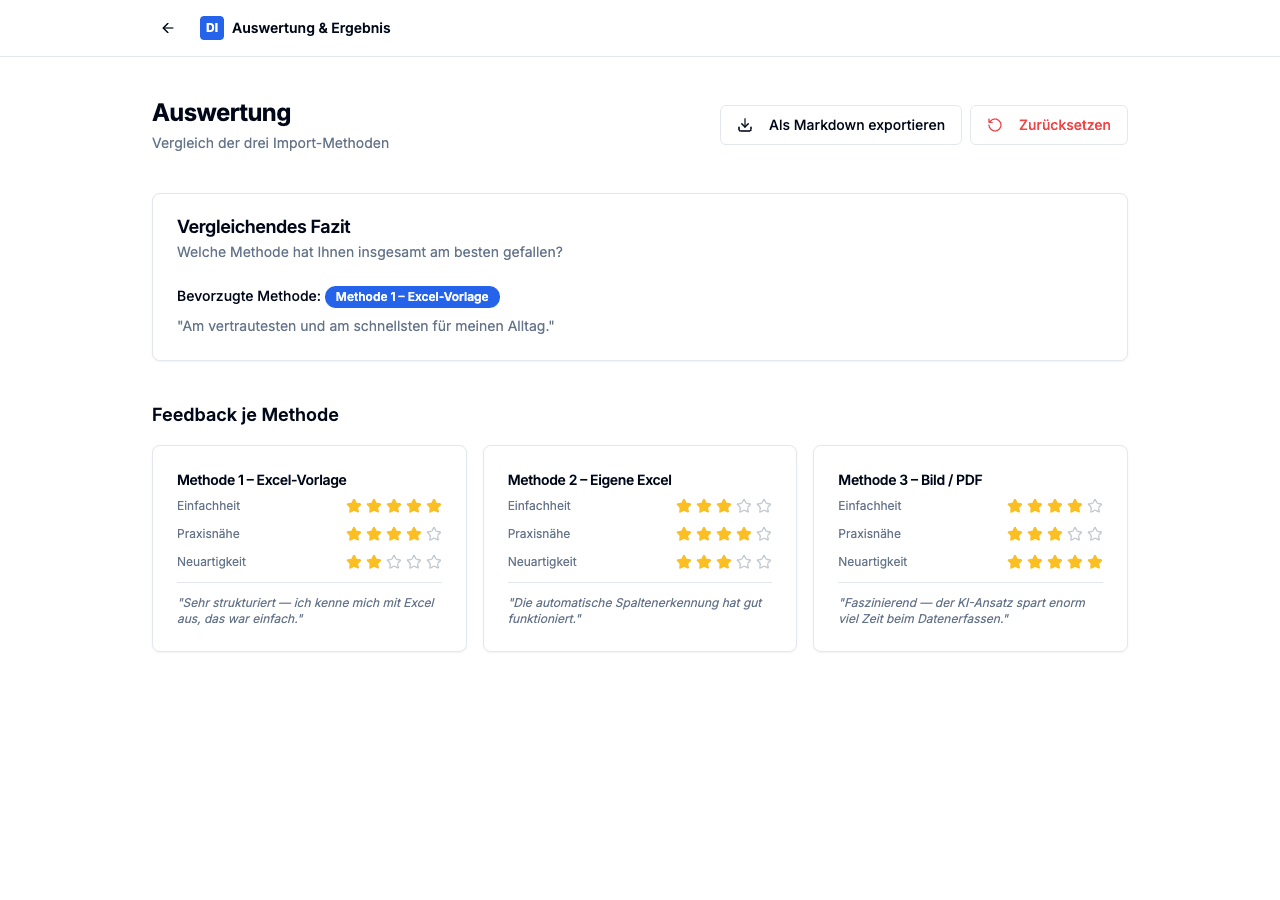 Methode 1 gewinnt in Einfachheit, Methode 3 begeistert durch Neuartigkeit.
Methode 1 gewinnt in Einfachheit, Methode 3 begeistert durch Neuartigkeit.
Wo es hakte – die ehrlichen Momente
Das interaktive CLI-Problem
Beim Setup wollte Claude npm create vite ausführen – ein Befehl, der interaktive Rückfragen stellt. Das funktioniert in einer automatisierten Umgebung nicht. Claude hat das erkannt, aber nicht sofort die richtige Lösung gewählt: Ein erster Versuch mit yes | wurde abgelehnt, ein zweiter mit einem anderen CLI-Trick scheiterte auch.
Die eigentlich elegante Lösung – alle Boilerplate-Dateien direkt zu schreiben statt über ein CLI-Tool – kam erst nach ein paar Minuten Hin und Her. Kein großes Problem, aber ein gutes Beispiel dafür, dass KI nicht immer den direkten Weg nimmt.
Der Dev-Server der nicht startete
Nach dem Setup wollte der Entwicklungs-Server nicht starten. Die Fehlermeldung war kryptisch: Failed to spawn process: No such file or directory. Das Problem lag daran, dass npm und node nicht im Systempfad verfügbar waren. Claude hat das diagnostiziert und behoben – aber erst nach zwei fehlgeschlagenen Versuchen mit falschen Pfaden.
Ich hab es genossen, das zu beobachten: KI debuggt nicht anders als wir Menschen. Sie liest die Fehlermeldung, formuliert eine Hypothese, testet sie, korrigiert.
Der State-Isolation-Bug
Nach meinem ersten vollständigen Durchlauf von Methode 1 war plötzlich Methode 3 als abgeschlossen markiert – obwohl ich sie nie gestartet hatte. Und Methode 2 war bei Schritt 3 von 6.
Das war mein Fehler beim Spezifizieren gewesen: Ich hatte nicht klar genug formuliert, dass jede Methode vollständig unabhängig von den anderen resettet werden soll, wenn man sie neu startet. Die Anforderung musste ich im Chat nachreichen. Claude hat die Lösung schnell implementiert, aber es zeigt: Unklare Anforderungen erzeugen subtile Bugs, die man erst beim echten Testen findet.
Die KI-Analyse-Animation
Methode 3 hat eine animierte KI-Analyse-Sequenz – ein 3-Sekunden-Ladevorgang der simuliert, dass eine KI die Tabelle im hochgeladenen Bild analysiert. Ich wollte davon einen Screenshot machen.
Das war überraschend schwierig. Die Animation lief immer schon durch, bevor der Screenshot-Befehl ausgeführt werden konnte. Es folgten mehrere Versuche: Date.now() einfrieren, den DOM direkt manipulieren, den Timer verzögern. Keiner davon hat sauber funktioniert. Am Ende habe ich diesen Screenshot übersprungen – manchmal ist das die pragmatischste Entscheidung.
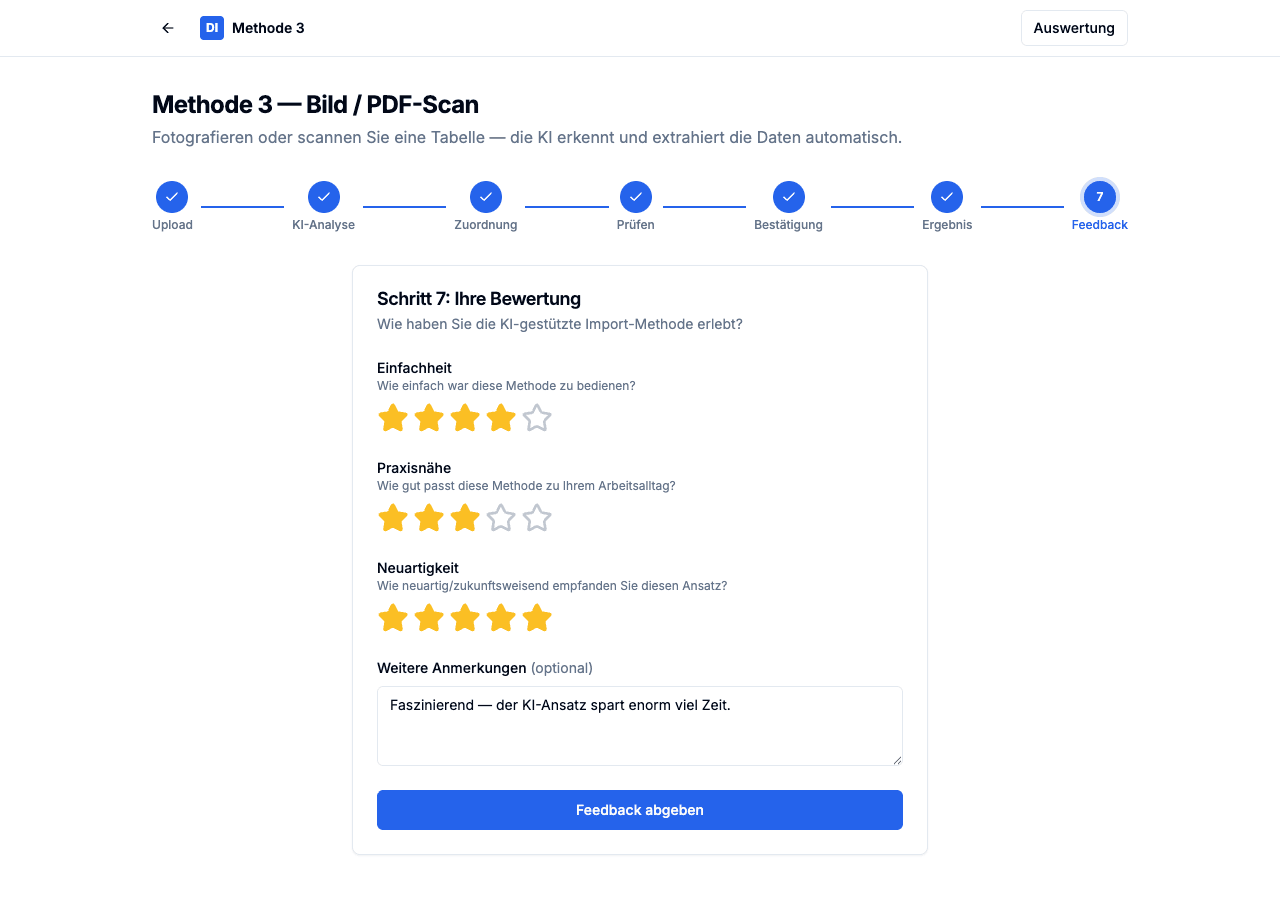 Das Feedback-Formular am Ende von Methode 3 – Einfachheit 4/5, Neuartigkeit 5/5.
Das Feedback-Formular am Ende von Methode 3 – Einfachheit 4/5, Neuartigkeit 5/5.
Was ich dabei gelernt habe
Prompting ist UX-Arbeit. Die Fähigkeit, eine Anforderung so zu formulieren, dass ein KI-System das Richtige baut, ist dieselbe Fähigkeit wie gutes Requirements Engineering. Wer als UX-Designer gewohnt ist, Nutzerbedürfnisse präzise zu formulieren, hat hier einen natürlichen Vorteil.
Plan first, build second. Ich hätte direkt "bau mir die App" schreiben können. Ich hätte mittelmäßige Ergebnisse bekommen. Die Investition in mehrere Planungsrunden – bevor eine einzige Datei angelegt wurde – hat die gesamte Bauphase stabiler gemacht.
KI macht keine Fehler, die du nicht machst. Alle wirklich schlimmen Bugs kamen aus meinen eigenen unklaren Anforderungen. Die technischen Fehler (Path-Probleme, CLI-Issues) hat Claude selbst gefunden und größtenteils selbst behoben. Was es nicht kann: aus einer ungenauen Anforderung eine genaue machen.
Schnelligkeit kommt mit Abstrichen. Zwei bis drei Stunden für einen voll funktionsfähigen Prototypen ist bemerkenswert schnell. Aber es ist kein poliertes Produkt. Es gibt ungenutzte Importe im Code, ein paar inkonsistente Labels, kein Accessibility-Audit. Das ist fine für einen Forschungsprototypen. Es wäre nicht fine für Production.
Das Ergebnis ist kein Design-Showcase – und das war Absicht. Als Designer achte ich normalerweise sehr auf Details: Abstände, Typografie, visuelle Hierarchie. Das stand hier bewusst nicht im Vordergrund. Das Ziel war ein funktionsfähiges Forschungsinstrument, kein ausgearbeitetes UI-Design. Wer die Screenshots anschaut, wird das sehen – und das ist in Ordnung so.
Das Ergebnis
Drei Importmethoden. Sechs respektive sieben Wizard-Schritte. Mock-Daten mit 15, 100 und 50 Einträgen. Inline-Editing. Persistenz über Browser-Neustarts. Auswertungsseite mit Markdown-Export. Eine portable ZIP-Datei zum Weitergeben.
Und das Wichtigste: Das Tool funktioniert. Ich kann es echten Testnutzern in die Hand geben, die reale Feedback-Daten erzeugen – über eine Simulation, die sich wie ein echtes System anfühlt.
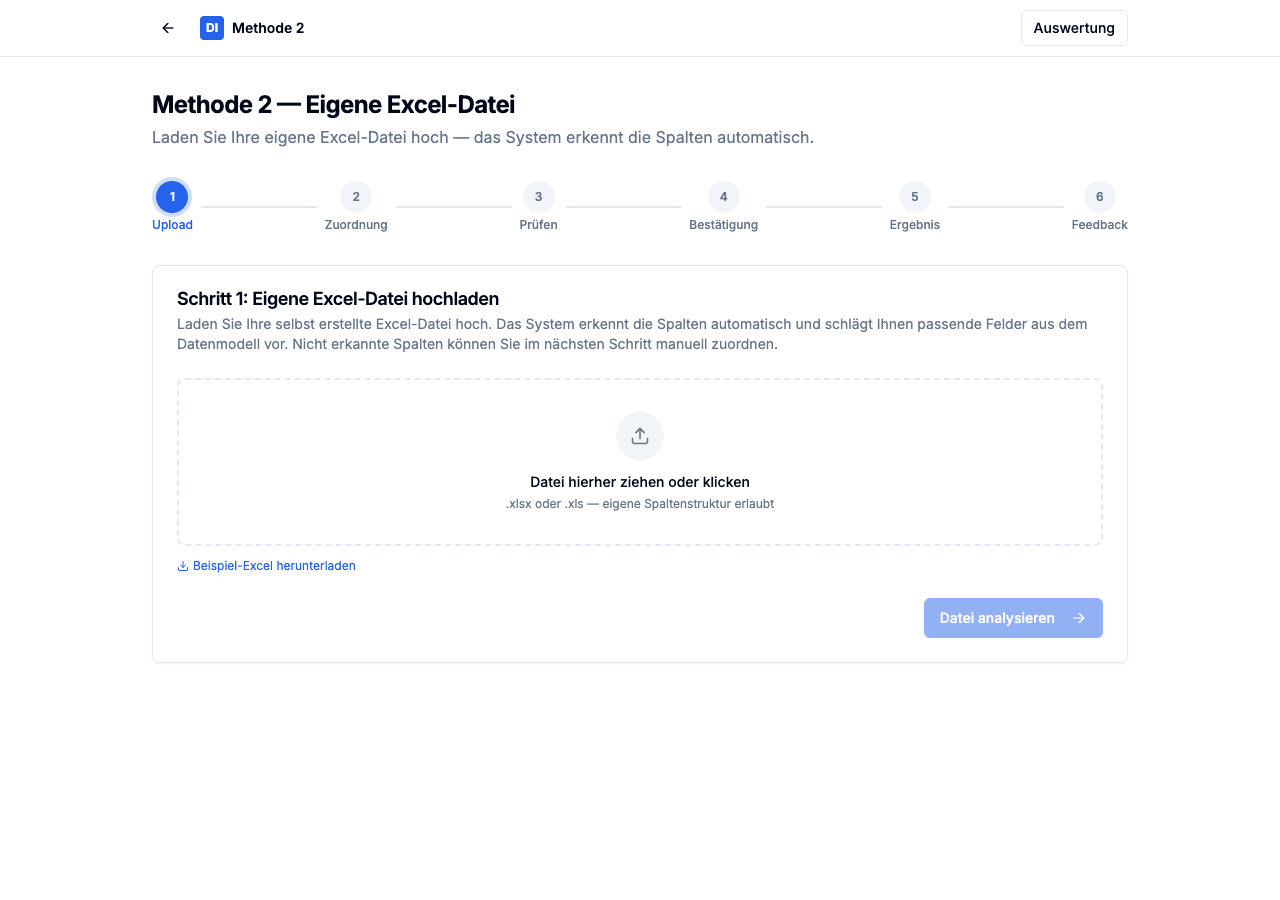 Der Upload-Schritt von Methode 2 – clean, minimalistisch, mit Beispieldatei zum Herunterladen.
Der Upload-Schritt von Methode 2 – clean, minimalistisch, mit Beispieldatei zum Herunterladen.
Das ist der Kern von KI-gestütztem UX-Prototyping: nicht die KI bauen lassen was sie will, sondern ihr präzise sagen was man braucht – und dann gemeinsam iterieren.
Dieses Experiment entstand als Teil meiner laufenden Forschung zu KI-gestützten UX-Methoden. Der Prototyp ist auf GitHub verfügbar: github.com/eltuctuc/datenimport-simulation
Dieser Artikel wurde mit Unterstützung von Claude (Anthropic) verfasst. Grundlage war der vollständige Chatverlauf der Entwicklungssession sowie die im Projekt entstandenen Screenshots. Die inhaltlichen Entscheidungen, Bewertungen und das Experiment selbst stammen von mir.